Writing prompts for Large Language Models (LLMs) suffer the same difficulties as humans communicating with each other.
A good analogy for communication is viewing what we say as a form of information compression. When I communicate an idea, the handful of complete sentences I write or speak are a shadow of the representation I hold in my own mind. This isn’t my own analogy, but one borrowed from a blog post by Alexandr Wang back in 2020: “Information Compression”.


It’s no surprise that writing extremely detailed instructions with few-shot examples performs reasonably well for prompting LLMs. This approach simply compresses less of our idea. And, just like in normal data compression, there are many different approaches to compress meaning into a prompt.
Today, most AI builders default to OpenAI-compatible chat-focused completion APIs. As a result, a lot of effort is fixated on crafting few-shot examples, engineering better prompts and context, or reaching for costly efforts in fine-tuning. None of this effort is irrational – if you assume that natural language is the best medium for prompting LLMs and structuring its outputs, these are obvious approaches to improve its performance.
But, this focus misses something deeper: natural language is a lossy communication medium. And more importantly, natural language is not the only useful medium. For a large class of problems, code is a significantly higher-fidelity medium. As a result, code can preserve far more meaning when communicating our intent to LLMs.
It’s important to note that communicating with LLMs isn’t a one-way act of compression. In communicating its response, these models are also compressing their own internal representation back into its response, which can be natural language or code.

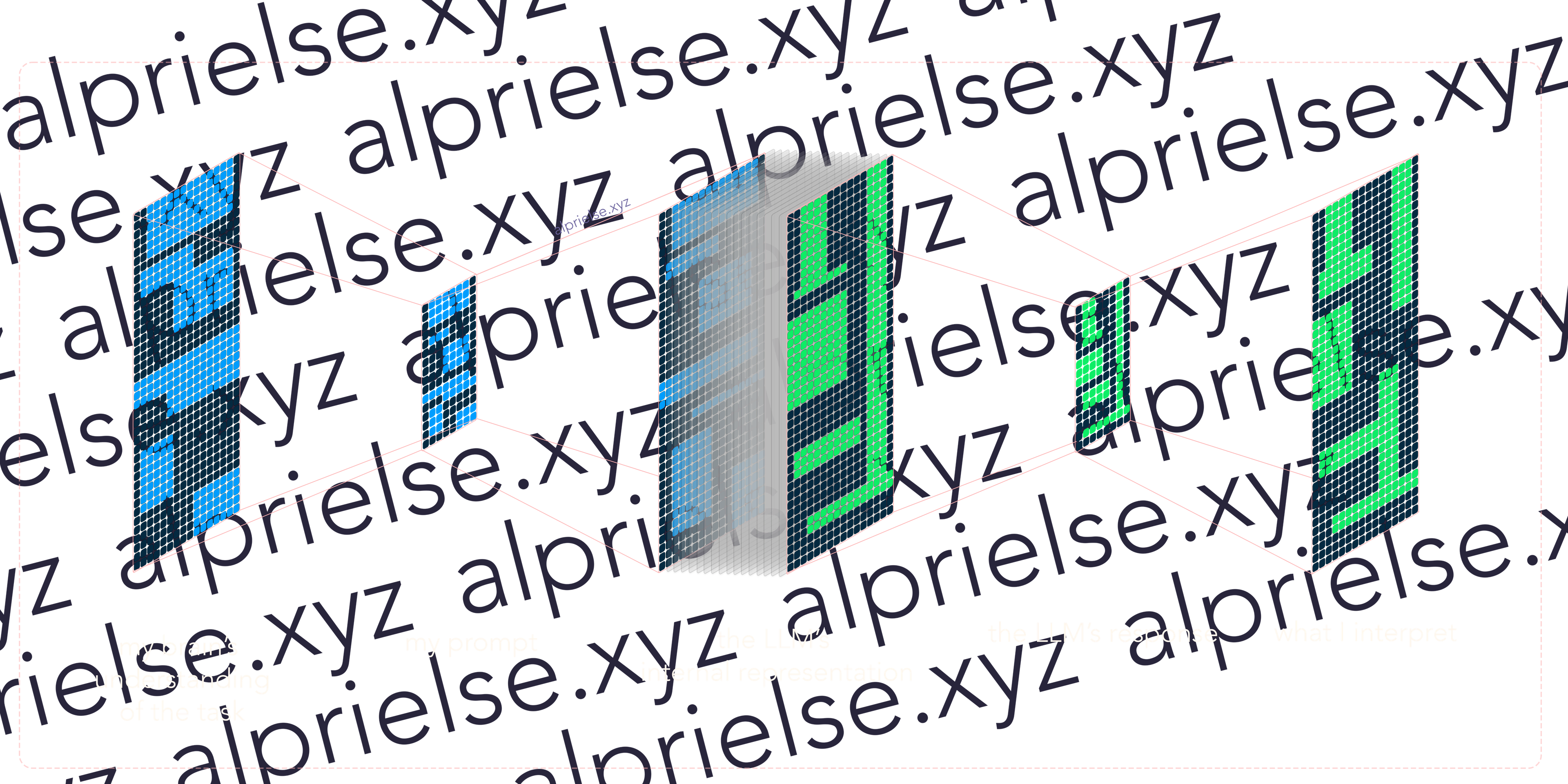
In building up an intuition for why code is a better medium for prompting, we can look at how the usage of LLMs is shifting towards using code when generating responses to communicate with external systems.
Tool-Calling and JSON-Mode
Today, LLMs often communicate to external systems via “tool calling” or schema-constrained JSON, generating well-structured responses that these external systems can parse and understand.
While LLMs can immediately use Constrained Decoding to generate well-formed JSON objects, these models don’t intrinsically have the ability to call tools. So, the model is further trained with hundreds of thousands of more examples structuring this tool-calling behavior with “special tokens”. For many LLMs, a “tool call” actually means generating a JSON object wrapped with some special <|tool_call|> token. Here’s what that looks like (example taken from source):
<|tool_call|>
{
"name": "get_current_weather",
"arguments": {
"location": "Austin, TX, USA"
}
}
<|end_tool_call|>
Leveraging JSON as a communication medium leverages a strong prior for representing structured data because these models have seen so many examples of JSON during training. The LLM is able to make use of this strong prior in its ”compression” when generating a response.
Tool-calling, in comparison, is a behavior bolted-on to LLMs. These special <|tool_call|> tokens are a made-up construct that relies on synthetic training data that doesn’t generalize to more complex tool-calling scenarios.
LLMs have seen thousands of examples with this invented tool-calling scheme. However, they’ve seen billions of examples of code.
Naturally, code seems like it would be a stronger prior for LLMs to better use external tools and APIs
Code-Executing Agents and Code-Mode
When LLMs interface with external systems using code, they perform dramatically better.
LLM agents with the ability to write and execute Python outperform regular JSON-based tool-calling (Wang et. al). More recently, both Cloudflare and Anthropic have written about Typescript-generating LLM agents.
- Anthropic: Code execution with MCP: Building more efficient agents
- Cloudflare: Code Mode: the better way to use MCP
All these examples point in the same direction: code is the highest-bandwidth, most semantically rich way for an LLM to express a plan and communicate a structured response. In other words, more meaning is preserved when the LLM is compressing its representation into a response.
So, why shouldn’t code also be the communication medium we use to express our prompts to the model?
Code as a Communication Medium for Prompts
Code offers a structured, semantically rich language—more expressive than YAML/JSON and more precise than natural language. And that richness works in both directions of our information compression communication analogy.
The key idea here: not only can the model better communicate with external systems through code, but we can also give the model better prompts by reframing problems as a code completion task.
In practice, this translates to prompting our model with an incomplete Typescript program that encodes the constraints of our task as function signatures, type definitions, and incomplete blocks of code. This incomplete Typescript program is littered with // TODO comments and our LLM solves our task by filling out the implementation.
By framing a task as code completion, the model’s output must not only satisfy syntactic and structural constraints, but also type-check according to programming semantics. This creates a narrower, more meaning-preserving output space and therefore allows stronger guarantees about correctness than schema-constrained JSON generation alone.
This approach isn’t universal — it doesn’t make sense for every task we use LLMs to solve. But, it shines in domains where response structure matters and these structures can be mapped to a specific programming language construct (e.g., variable binding, control flow, function application, etc).
Somewhere along the way, we stopped questioning the ubiquitous natural language, chat-focused interface. LLMs feel so conversational and human-like that we instinctively treat them like humans, quietly anthropomorphizing them into something we can “prompt” in the same way we talk to other people.
By expressing our problems in code, we are using a better medium for communicating the structure and constraints of our task — one that aligns far more closely with how LLMs already represent reasoning internally.
The follow-up to this post is a technical walkthrough of an implemented prototype of this approach in action. In it, we’ll dive into a product prototype similar in spirit to something like Clay.com or freckle.io and how we can map Suggestive UI for creating new columns in the product to a “variable binding” code completion problem.
Thank you to Claire Yang for our spirited discussions and help editing this write-up!